
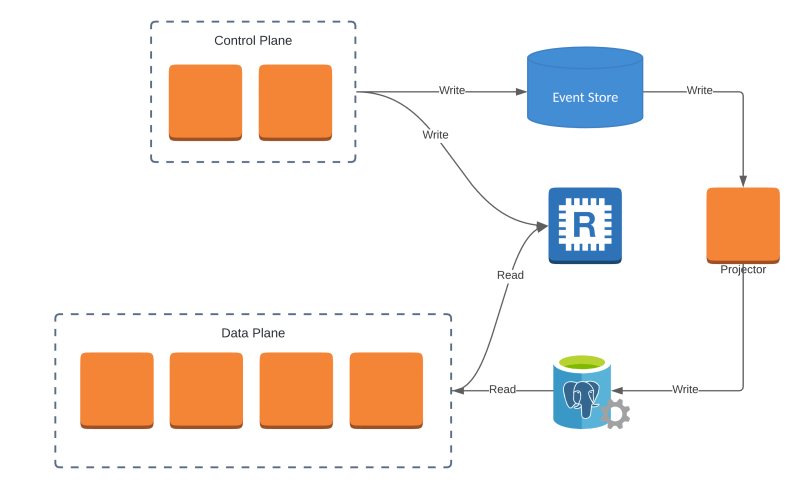
An architect I was recently speaking with at work mentioned an architectural approach to designing our systems to make them highly available and independently scalable based on the resources used. This concept is called control plane and data plane.
The control plane and data plane concept is worth considering if you deal with high traffic volumes where being highly available is a priority.
You will undoubtedly find many networking articles when searching for information on control planes and data planes. There are many examples and descriptions of how networking applies this. For example, the following from Cloud Flare describes the difference between the control plane and the data plane. “The control plane is the part of a network that controls how data is forwarded, while the data plane is the actual forwarding process.”
“Control plane and data plane are terms of art from networking, but we use them all over the place within AWS” – Becky Weiss & Mike Furr.
AWS has applied this terminology into engineering and applied the principles set out by networking to describe a way of separating logical parts of the system. The main focus is to split functionality based on controlling the data (Control Plane) and retrieving the data (Data Plane). The goal is to create highly available systems that can still serve customers when parts of the system are down.
Control Plane and Data Plane
The control plane and data plane are networking terms used to explain how to split logic out into distinct areas.
AWS has used these terms to explain how to split their architecture to allow for high availability and targeted scaling based on areas of the architecture that deal with more significant throughput.
If we focus on the AWS terminology of control plane and data plane
Control Plane – Deals with changes to the system. Changes such as creating, saving, deleting and updating of resources. The control plane also handles propagating any changes made.
Data Plane – Deals with the runtime activity of our systems.
An example of a control plane and data plane could be that when a user sets up Multi-Factor Authentication (MFA), the control plane will handle the set-up such as saving TOTP or a Backup MFA method to our database. If you were using an event-style architecture, the control plane would also deal with new or updated events and propagate them to a database.
The data plane would deal with retrieving this information from the database.

Advantages of separating the Data Plane and Control Plane
High availability
Most of our systems need to be highly available. However, issues occur, and we need to build our systems in a way where we have anticipated and planned for system degradation.
“One lesson Amazon learned is to expect impairments before they happen” – Becky Weiss & Mike Furr
Separating our application logic into a control plane and data plane allows us to focus our attention on the most critical systems to have up and running. The most critical system here is the data plane.
Our control plane still needs to be reliable and as available as possible, but if a service went down, we would want it to be the control plane and have the data plane still serving our customers.
The control plane often has more moving parts than the data plane. This is because the control plane deals with creating, saving, deleting and updating resources. Due to this, the control plane has a higher risk of something going wrong where the data plane retrieves the user’s data.
AWS uses this concept to provide highly available systems. If a dependency goes down, we might not get any new or updated resources, but the system is still up and running, able to serve customers, even with outdated data. Ref: https://aws.amazon.com/builders-library/static-stability-using-availability-zones/
Scaling
When splitting logic into a data and control plane, we will see that the data plane receives a higher volume of requests than the control plane.
On this basis, it makes sense that we can scale these services independently to allow us to scale tasks based on what endpoints and requests are being made.
Downsides to the Control and Data Plane
The control plane and data plane is a great architecture to be followed in some situations.
It’s easy to over-engineer solutions, increasing scope and slowing down the delivery time. I’ve done this myself. It’s easy for the solution to become more complex. This can increase the time it takes to understand the solution before being able to develop in it.
“When your design or code actually makes things more complex instead of simplifying things, you’re over-engineering.” – Max Kanat-Alexander
When deciding on the architecture of your system, you want to have a solid plan. Your plan should include things like
- A clear understanding of the requirements, both funcational and non functional
- Understand what each component in your design will be doing
A post by Lucidchart dives into this area more “How to design software architecture: Top tips and best practices“
Summary
The control plane and data plane architecture is great to follow when developing services to be highly available and independently scalable. However, before committing to it, make sure to research and ensure it’s the correct architectural pattern for you to follow for the solution you are building.
It would be great to hear from anyone with any thoughts on this post, or if you have used a similar style before, I would love to hear from you in the comments below.
